Specifying properties
For native win32 controls most of the required properties, and patterns are already implemented. There are instances, however, when some of these default properties are missing, or are incorrect. We can use OS API to specify these properties. Note that doing this will work only when IRawElementProviderSimple::GetPropertyValue() interface is implemented by OS. If you are implementing the interface yourself, and not calling the OS version of the interface, then specifying this property via the OS API wont do anything.
Such a technique where the accessibility to a control is provided via proxies (by the OS), but the application (or the control) itself specifies some of the properties is called
dynamic annotation. There are three types of dynamic annotation:
- Direct annotation (IAccPropServices::SetPropValue(), IAccPropServices::SetHwndPropStr(), etc.): Direct annotation is used to specify properties which stay constant over time, and is the one we will be studying here.
- Value-mapped annotation (say for certain slider controls, uses IAccPropServices::SetHwndPropStr(), etc.): Value mapped annotation can be used to specify a mapping for the values/strings displayed in a control to some other value. Eg. in a slider control we may have 0, 1, 2, etc. as ticks. These may represent different resolutions of a display in a setting application. Without annotation AT will read the values as 0, 1, 2, etc. but we can use annotation so that AT will read 0 as 800x600, 1 as 1280x720, and so on.
- Server annotation (IAccPropServices::SetPropServer(), IAccPropServer, etc.). This can be used to associate a class with a control item. The control item may be a whole window, or one of the sub elements of its UI. Whenever the AT gets properties for the item it calls the class methods. This will have a blog post of its own.
Via RC files
For some controls, the name property can be specified from within RC file itself. It is fairly simple and explained
here. This method is quite limited as only the name property can be specified , and it can only be used with some controls.
Using COM API
IAccPropServices* pAccService = nullptr;
CoCreateInstance(__uuidof(CAccPropServices), nullptr, CLSCTX_INPROC, IID_PPV_ARGS(&pAccService));
Now we invoke
SetHwndPropStr() on this interface. For example this is how we set name.
TCHAR *NameStr = _T("Press Me");
pAccService->SetHwndPropStr(hWnd, (DWORD)OBJID_CLIENT, (DWORD)CHILDID_SELF, Name_Property_GUID, NameStr);
Here OBJID_CLIENT indicates that we are referring to the whole window (or just the client area if the window has non client area as well) represented by hWnd. CHILDID_SELF indicates that we are referring to the control rather than one of its children.
You must include "initguid.h", and "UIAutomation.h" header files. Include "initguid.h" first.
As these are com API, you will have to initialize COM before using them.
In the Accessibility Insights screenshot given above we can see that the "HelpText" property does not exist. Let us use this COM API to specify it.
TCHAR* HelpTextStr = _T("This button is used to demonstrate accessibility API");
pAccService->SetHwndPropStr(hWnd, (DWORD)OBJID_CLIENT, (DWORD)CHILDID_SELF, HelpText_Property_GUID, HelpTextStr);
Here is what Accessibility insights now reports for this control. Compare the "HelpText" property with the that in the previous screenshot.
Do cleanup when your control is getting destroyed.
MSAAPROPID props[] = { Name_Property_GUID, HelpText_Property_GUID };
pAccService->ClearHwndProps(GetSafeHwnd(), (DWORD)OBJID_CLIENT, (DWORD)CHILDID_SELF, props, ARRAYSIZE(props));
pAccService->Release();
CoUninitialize();
The sample code for all this is present on
Github. Check InitAccessibility(), and DeInitAccessibility() methods in 01MFCDialogSimple project.
A note on Object ID (idObject), and Child ID (idChild) [3]
HRESULT SetHwndPropStr(
[in] HWND hwnd,
[in] DWORD idObject,
[in] DWORD idChild,
[in] MSAAPROPID idProp,
[in] LPCWSTR str
);
hwnd, idObject, and idChild together refer to a UI element. 'hwnd' refers to the window of a control.
idObject refers to the kind of object within the window (specified by hwnd) we want to refer to.
Here are some of the values it can take.
- OBJID_CLIENT: Refers to window's client area. It excludes non client area (frame, etc of the window)
- OBJID_WINDOW: Refers to the whole window. This includes the client area (OBJID_CLIENT), and non-client area
- OBJID_TITLEBAR; Refers to the title bar of the window
- OBJID_HSCROLL: Windows horizontal scroll bar
- OBJID_VSCROLL: Windows vertical scroll bar
- OBJID_CARET: caret in the window
- OBJID_CURSOR: mouse pointer
- Other values (from WinUser.h): OBJID_SYSMENU, OBJID_MENU, OBJID_CLIENT, OBJID_SIZEGRIP, OBJID_ALERT, OBJID_SOUND, OBJID_QUERYCLASSNAMEIDX, OBJID_NATIVEOM
idChild is used to specify one of the child controls within the Window. The Child ID can either be obtained via either the IEnumVARIANT interface if the control supports it, otherwise the child ID are usually in increasing integral order starting with 1. A special value CHILDID_SELF refers to the object itself rather than one of its children.
Specifying properties for non window (non hwnd) controls
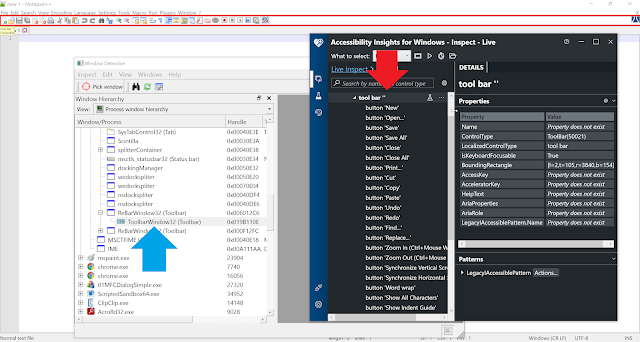
Frequently we encounter controls which don't have a window of their own. For example in the toolbar control of
notepad++ we can see that the child controls of the toolbar are not a window in themselves. The toolbar is a window, and draws the child controls as bitmaps within itself.
 |
| Notepad++ toolbar |
In this image we can see that while
Window Detective does not show any children of the toolbar,
accessibility insights does. This is because the buttons shown in the toolbar are not individual windows hence Windows Detective is not able to detect them. Accessibility insights on the other hand uses automation to enumerate child controls of the toolbar (perhaps via IAccessible interface), and the toolbar is able to convey information about the children it has.
To make things simpler I have modified our MFC dialog so that it now has a toolbar. The toolbar has a background of red cross lines. It has 2 buttons - Button 1, and Button 2. When you compare outputs of Window Detective, and accessibility insights in the following image you see observations similar to notepad++, ie. the buttons are not listed in Window Detective, but are listed in accessibility insights.
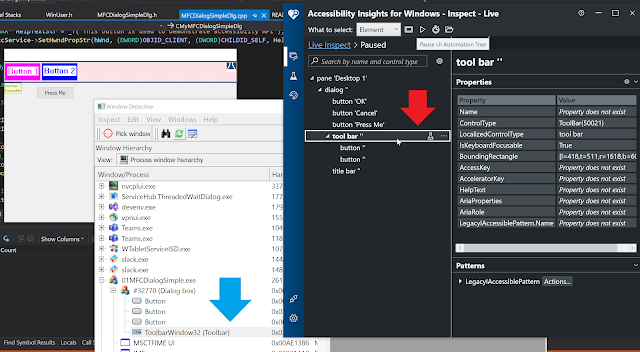 |
| MFC Simple Dialog with toolbar |
Let us use this to understand how properties for non-window controls can be specified (Button 1, and 2 above). The toolbar does not support IEnumVARIANT interface (which can be seen from Patterns pane of accessibility insights), thus it is safe to assume that child Id would be 1, and 2 respectively for the two buttons. You can also use tools like
Inspect to obtain child id.
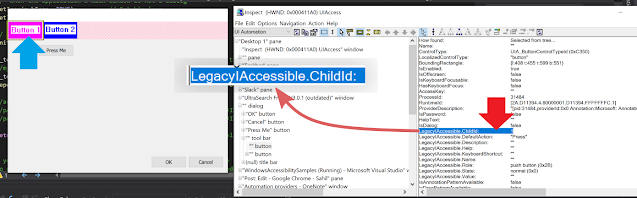 |
| Child ID from Inspect.exe |
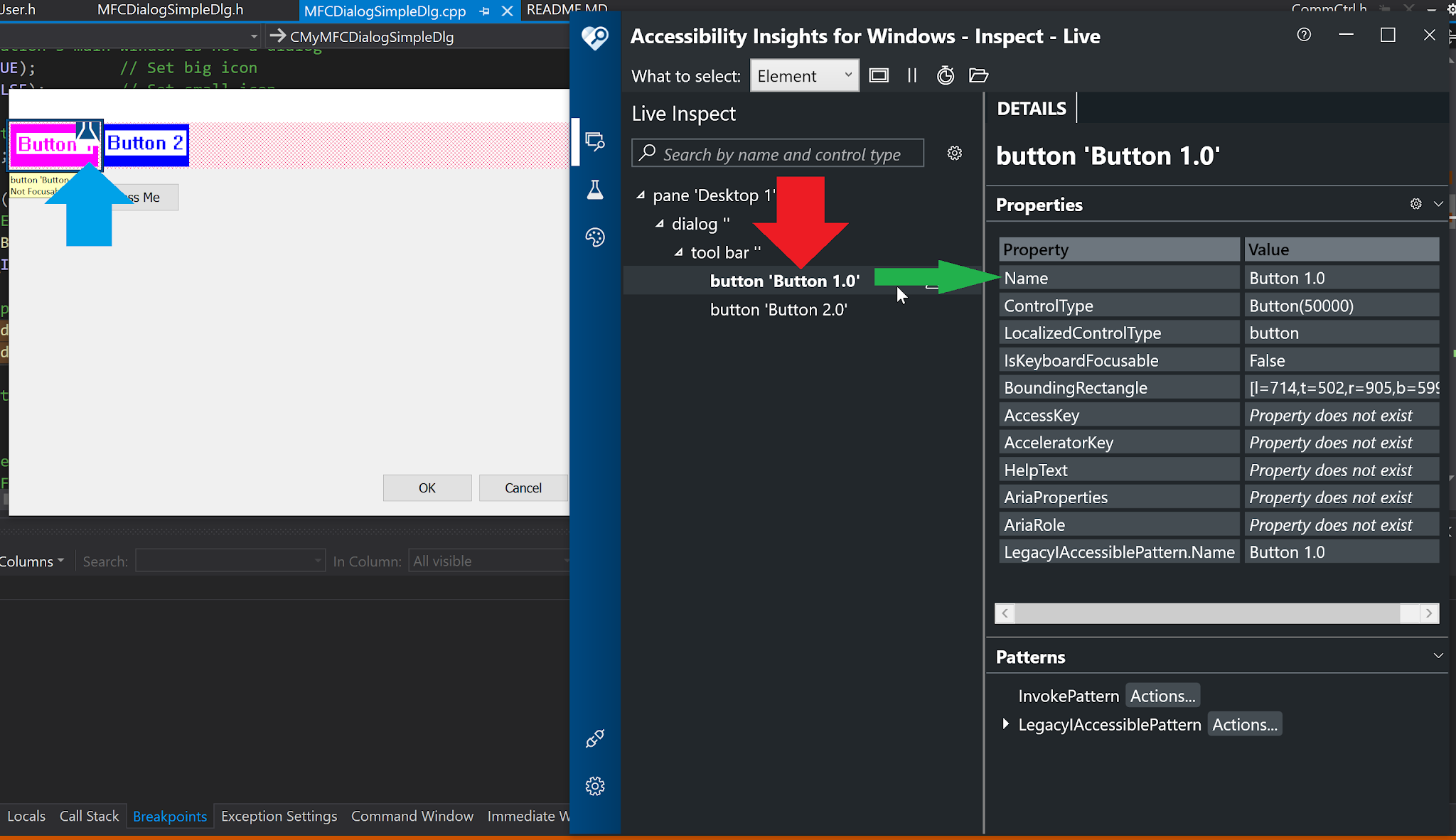
Let us see the properties reported by Accessibility insight for button 1.
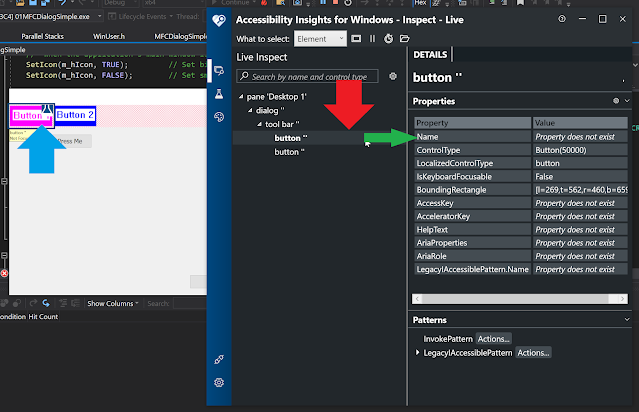 |
| Name property for button 1 doesn't exist |
Notice that the Name property does not exist. We will now use the IAccPropServices::SetHwndPropStr interface once more to set this, but this time we will pass integers 1, and 2 for the two buttons, instead of CHILDID_SELF.
pAccService->SetHwndPropStr(m_toolbar1.GetSafeHwnd(), (DWORD)OBJID_CLIENT, (DWORD)1, Name_Property_GUID, _T("Button 1.0"));
pAccService->SetHwndPropStr(m_toolbar1.GetSafeHwnd(), (DWORD)OBJID_CLIENT, (DWORD)2, Name_Property_GUID, _T("Button 2.0"));
Take a note of the hwnd, object Id, child ID, and the value of string parameters passed above. Let us see what accessibility insights reports now.
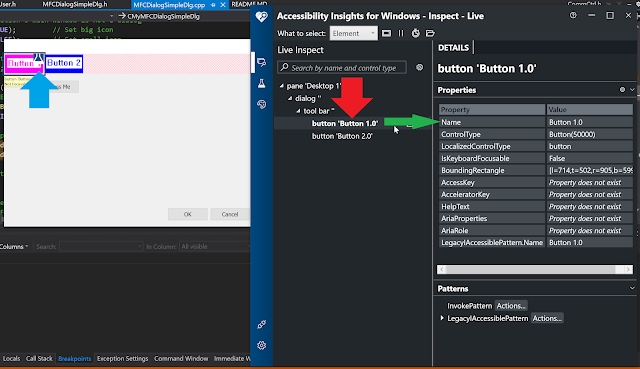 |
| Name property for button 1 now set |
The name property is now being reported corrected.
As mentioned before, the sample code for all this (updated to include the toolbar) is present on
Github.
References